Relevance Modeling Approach
to Handwritten Historical Document Retrieval
T. M. Rath, R. Manmatha, V.
Lavrenko [trath, manmatha, lavrenko]@cs.umass.edu
Idea
Words that appear in a historical document are treated as having a dual
representation: an image form
and the corresponding annotation
(or label). In the relevance model retrieval framework, the image form
of a word is represented with terms from a discrete image vocabulary. This vocabulary
can be seen as forming a language, just like French or any other kind of
language.
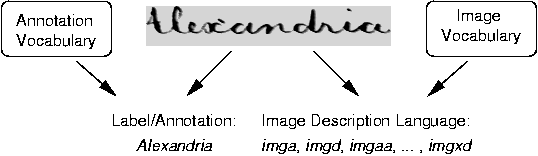 |
Figure 1: Illustration of the dual representation concept of words
|
Once we are presented with an ASCII query in English (e.g. 'Wilper'),
the goal is to find (retrieve) images of words, which are likely to be
"translations" of the query in the image language. The approach here is
inspired by the success of the cross-language
information retrieval
(CLIR) approach based on relevance modeling. In the CLIR
framework, documents in a foreign language (e.g. French) are retrieved
using queres in a
familiar language (e.g. English).
Retrieval Approaches
Probabilistic Annotation
The probabilistic annotation model annotates each word image in the
collection with all possible
annotations/labels. That is, a particular word image could have any
given ASCII annotation. Each of these annotation has an attached
probability, to express the uncertainty about the labeling. The per-word
image annotation probabilities form a probability
distribution over the entire annotation vocabulary that is
considered.
For the retrieval of documents, all word-level annotation distributions
in a document are averaged to obtain an approximate document language model. These
language models can then be used with classical information retrieval
approaches. We use the query-likelihood
ranking approach to perform retrieval.
Kullback-Leibler Scoring
In the probabilistic annotation model, the mapping from the image
language to the annotation language (English) is done beforehand, and
the retrieval operates on the probabilistic annotations, that is, in
the annotation vocabulary space.
In the KL-scoring approach, a given query is mapped into the image
language at query time. The result is a distribution over image vocabulary
terms, the query model. In order to rank word images in the collection,
their word image model (image vocabulary distribution) is compared to
the query model using Kullback-Leibler divergence. Due to the realtime
query 'translation' into the image language, this approach has a longer
per-query processing time.
Demonstration Systems
Currently, three demonstration systems are available:
 Line Retrieval using probabilistic
annotation: This is the first retrieval system that was built for
line retrieval. The collection size is 20 pages, which equals 657
lines. 90% of the collection was used for training, 10% (i.e. ~65
lines) to build the retrieval system. Quantitative results on this
dataset are available. They indicate average precision scores
between 54% and 89% for 1-word to 4-word queries respectively
[2].
Line Retrieval using probabilistic
annotation: This is the first retrieval system that was built for
line retrieval. The collection size is 20 pages, which equals 657
lines. 90% of the collection was used for training, 10% (i.e. ~65
lines) to build the retrieval system. Quantitative results on this
dataset are available. They indicate average precision scores
between 54% and 89% for 1-word to 4-word queries respectively
[2].
- Page retrieval using probabilistic
annotation: The collection size is roughly 1000 pages, with an
additional 100 training pages. This demo uses the reordering
approach described in [1], so only 1 query term is allowed [1].
- Page retrieval using Kullback-Leibler scoring (will be available in the future): This uses the
same collection as above. KL-scoring only supports 1-word queries
[1].
All datasets used for retrieval were automatically segmented using a
scale-space approach [3].
Publications
[1] T. M. Rath, R. Manmatha and V. Lavrenko:
A Search Engine for Historical Manuscript Images.
To appear in the Proc. of the ACM SIGIR 2004 conference, Sheffield,
UK, July 25-29.
[2] T. M. Rath, V. Lavrenko and R. Manmatha: A Statistical Approach to Retrieving Historical Manuscript Images without Recognition. CIIR Technical Report MM-42, 2003.
[3] R. Manmatha and N. Srimal: Scale Space Technique for Word Segmentation in Handwritten Documents. In: Proc. of the Second Int'l Conf. on Scale-Space Theories in Computer Vision. Corfu, Greece, September 26-27, 1999, pp. 22-33.