Word Spotting for
Handwritten Historical
Document Retrieval
T. M. Rath, R. Manmatha et al.
[trath, manmatha]@cs.umass.edu
Idea
Due to the great amount of
variability in handwriting and the high noise levels in historical
documents, handwritten historical documents are currently transcribed by
hand. In essence, this means that each occurrence of a word in a corpus
must be annotated. The goal of the Word Spotting idea applied to
handwritten documents is to greatly reduce the amount of annotation work
that has to be performed, by grouping all words into clusters. Ideally,
each cluster contains words with the same annotation (see Figure 1).
Once such a clustering of
the data set exists, the number of words contained in a cluster can be
used as a cue for determining the importance of the word as a query
term. For example, highly frequent terms, such as the, of,
etc. are stop words and can be discarded. All clusters with
terms that are deemed important can then be manually annotated. This
makes it possible to construct a partial index for the analyzed document
collection, which can be used for retrieval.
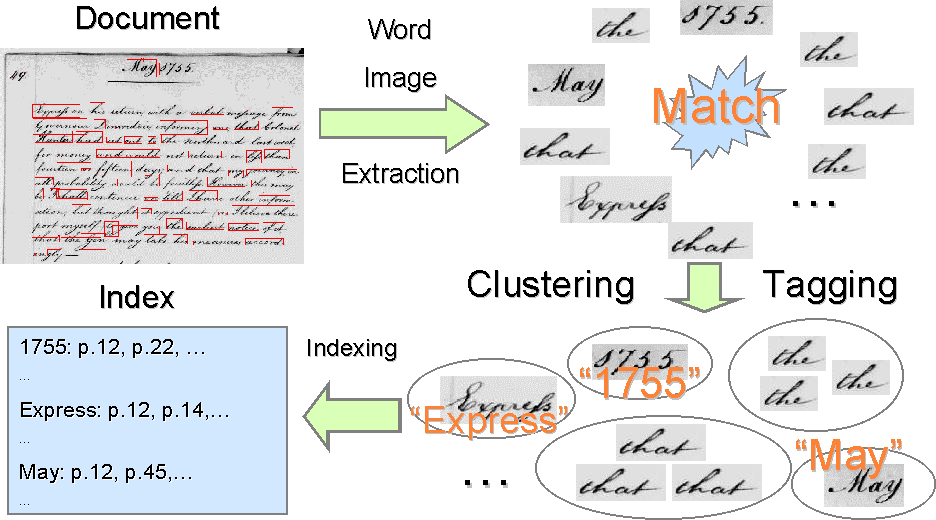 |
Figure 1: Illustration of the Word Spotting idea
|
Details
Figure 1 illustrates the
entire Word Spotting process from a document collection to a partial
index for the collection. In the first step, all documents in the
collection are segmented to obtain words. Then, pairwise word image
comparisons are made with a word image matching algorithm to provide
similarity information that is needed by the clustering algorithm. Once
the clustering of the data has been completed, selected clusters are
manually labeled with the ASCII-equivalent of the word images in that
cluster. This establishes a partial annotation of the collection, which
can then be used for building an index that allows retrieval. The
supported queries are those that have been used in the cluster
annotation.
At the heart of the Word
Spotting idea is the word image matching algorithm. Its accuracy and
efficiency determine the quality of the clustering and the size of the
collection that can be processed using the Word Spotting process. Since
the number of word image pairs grows as a quadratic polynomial in the
size of the collection, the per-pair matching time must be small.
We assume that the entire
collection is written in one author's hand, which reduces the amount of
handwriting variations that have to be compensated for. The following
section gives a brief description of the currently best performing word
image matching algorithm, which is based on Dynamic Time Warping (DTW).
DTW Word Image Matching
Algorithm
The Dynamic Time Warping
(DTW) algorithm is widely used for comparing time series with non-linear
distortions in the time axis. When a handwritten word image is
represented with shape features that result from sampling a function of
the image at each image column, DTW can be applied to word image
matching. In that scenario, the horizontal image axis becomes the time
axis and DTW simultaneously recovers correspondences between image
columns in two images and compares the feature values. The matching
distance between the word images is the sum of the distances between
corresponding features.
|
|
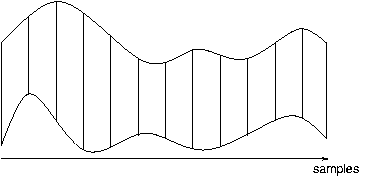
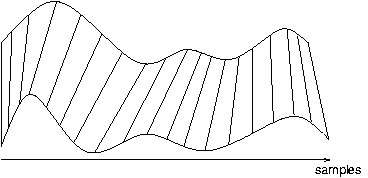
(a) linearly
stretched, with 1-1 comparison, � � �� �
|
� � � �
�(b) non-linear alignment with DTW.
|
| Figure
2: Alignment of two time series using linear stretching and Dynamic
Time Warping. |
Figure 2 shows the superior alignment accuracy of DTW over linear
alignment with 1-1 comparison of samples: in the latter case, samples
that do not correspond are compared, whereas the Dynamic Time Warping
Algorithm allows non-linear distortions of the time axes of both
signals. The resulting correspondences are usually very intuitive.
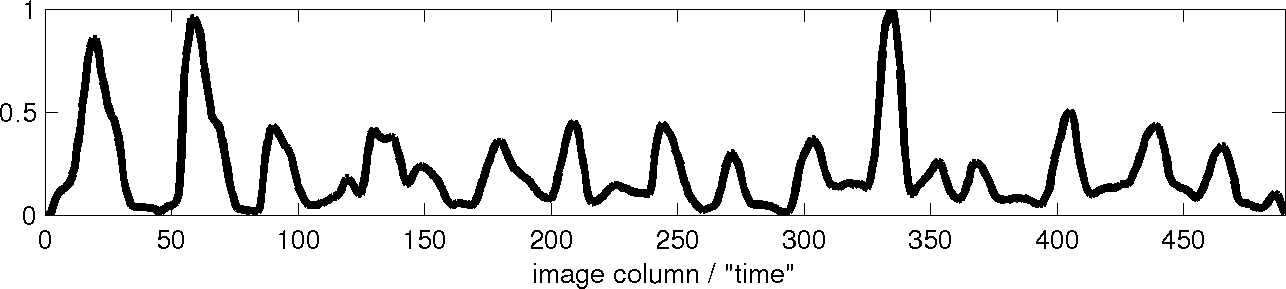
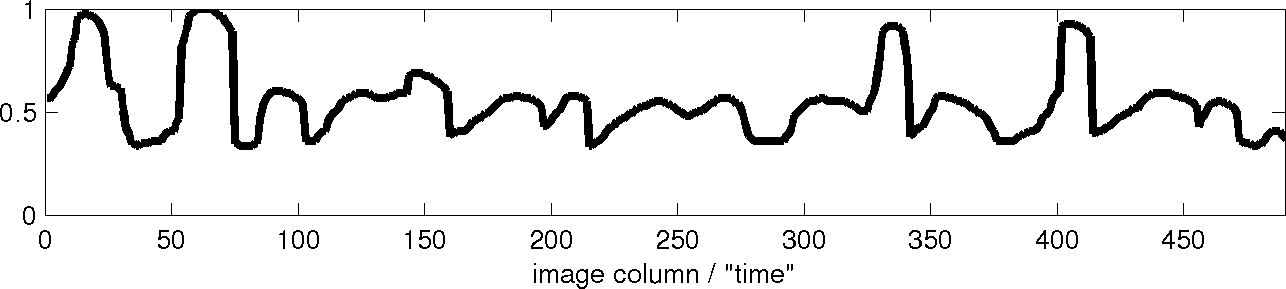
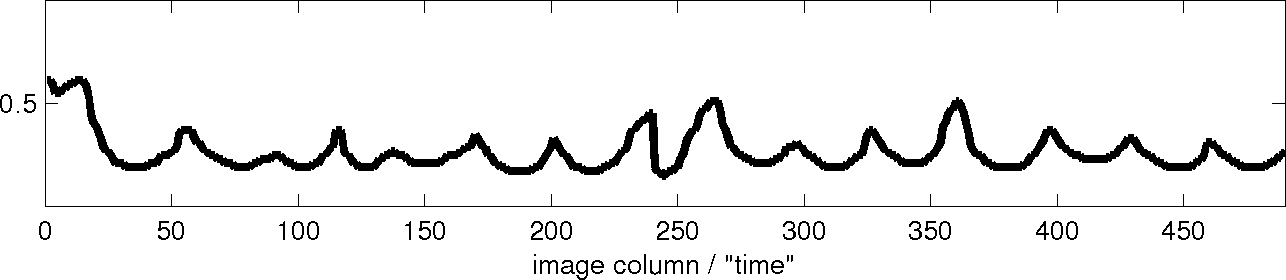
Figure 3 shows an original word image and 3 of the 4 profile shape
features that were used with the DTW word image matching algorithm [1].
The three features are
- Projection profile: each data point in the feature profile ("time
series") is the sum of the pixel intensities in the corresponding
column. We invert this value, since the result is visually more
appealing: long vertical components yield peaks in the profile.
- Upper word profile: in each column, the distance from the top of
the bounding box to the closest ink pixel in that column is calculated.
This results in probably the most intuitive feature.
- Lower word profile: same as the upper word profile, but
calculated from the bottom of the bounding box.
Publications
[1] T. M. Rath and R. Manmatha: Word Image
Matching Using Dynamic Time Warping. In: Proc. of the
Conf. on Computer Vision and Pattern Recognition (CVPR), Madison,
WI, June 18-20, 2003, vol. 2, pp. 521-527.
[2] T. M. Rath and R. Manmatha:
Features for Word
Spotting in Historical Manuscripts.
In: Proc. of the 7th Int'l Conf. on Document Analysis and Recognition
(ICDAR), Edinburgh, Scotland, August 3-6, 2003, vol. 1, pp. 218-222.
[3] J. L. Rothfeder, S. Feng and T. M. Rath: Using Corner Feature
Correspondences to Rank Word Images by Similarity. In: Proc. of
the Workshop on Document Image Analysis and Retrieval (DIAR), Madison, WI,
June 21, 2003.
Earlier Work
[4] T. M. Rath, S. Kane, A. Lehman, E. Partridge and R. Manmatha: Indexing for
a Digital Library of George Washington's Manuscripts - A Study of
Word Matching Techniques. CIIR Technical Report MM-36,
2002.
[5] S. Kane, A. Lehman and E. Partridge: Indexing George
Washington's Handwritten Manuscripts. CIIR
Technical Report, 2001.
[6] R. Manmatha and N. Srimal:
Scale Space Technique for Word Segmentation in Handwritten
Documents . In: Proc. of the Second Int'l Conf. on
Scale-Space Theories in Computer Vision. Corfu, Greece, September
26-27, 1999, pp. 22-33.
[7] R. Manmatha and W. B. Croft: A draft
of Word Spotting: Indexing Handwritten Manuscripts. In:
Intelligent Multi-media Information Retrieval, Mark T. Maybury,
Ed. MIT Press, Cambridge, MA, 1997, pp. 43-64.
[8] R. Manmatha, C. Han and E. Riseman:
Word Spotting: A New Approach to Indexing Handwriting
. In: Proc. of the IEEE Computer Vision and Pattern
Recognition Conference, San Francisco, CA, June 1996, longer
version available as UMass Technical Report
TR95-105.
[9] R. Manmatha, Chenfeng Han, E.M. Riseman and W.B. Croft:
Indexing Handwriting Using Word Matching. In: Proc. of
the First ACM Internal Conference on Digital Libraries, Bethesda,
MD, March 1996, pp. 151-159.